
Whilst generative AI isn’t a new concept. Unlike traditional AI technologies, generative AI doesn’t predict or classify based on input; it generates content and images based on text input. This form of AI first became popular in 2014, through the introduction of Generative Adversarial Networks (GANs). In this post, I’ll focus mostly on image generation aspect of generative AI. Previously, I’ve looked at AI-powered content generation platforms like Copy.ai, which is competing in this space with startups such as Jasper and Copysmith.
A GAN is a deep learning method through which one can create realistic images or transfer the style of one image to another (think of so-called ‘deepfakes’ where the images and videos are modified to swap one person’s face for another). But because we’ve seen a number of exciting generative models and applications this year it feels like generative AI is on a path to becoming more mainstream in its application.
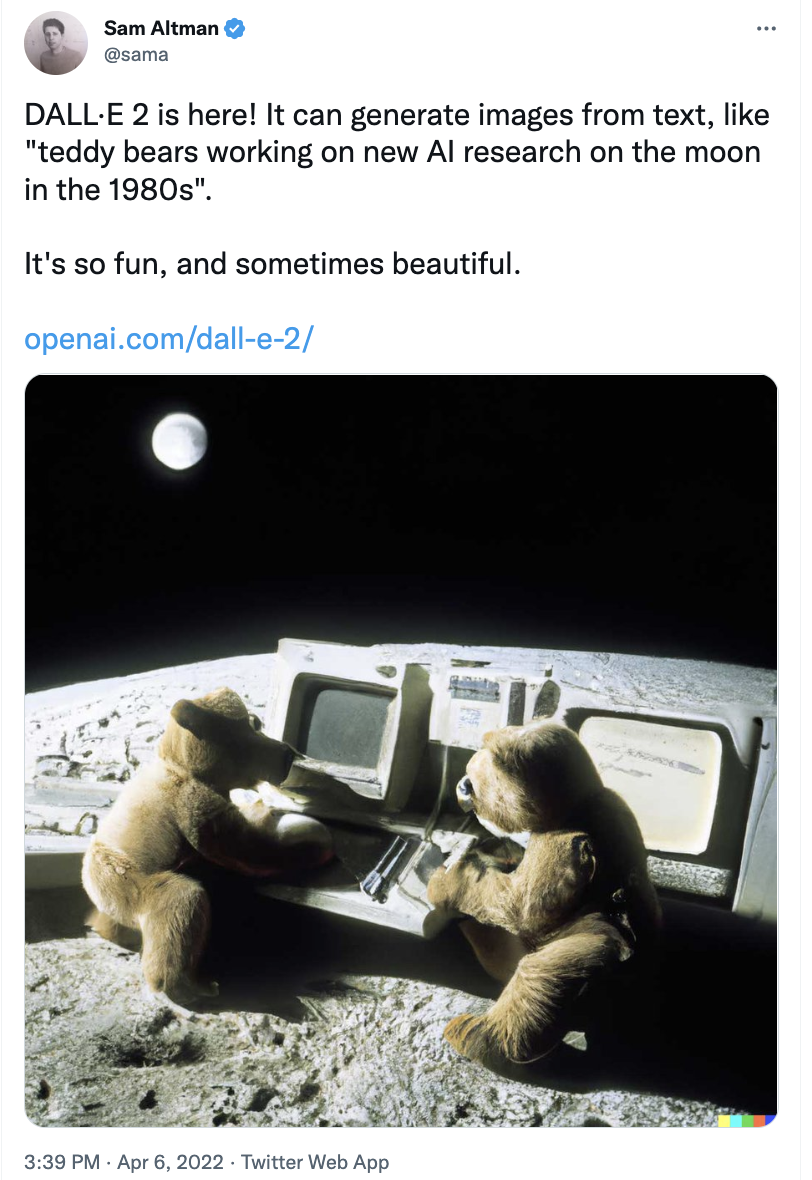
Earlier this year we saw the launch of DALL-E 2, a new machine learning model that can create images from a scene written in words (called a “prompt”).
Users provide DALL-E 2 with a text description and it generates an image in return. ‘Feature Learning’ is at the heart of generative AI; the neural network transforms pixel colours into a set of numbers that represent the features of the image. These features form the ‘input’ and are then mapped to the ‘output’ layer. This process is called “diffusion”; it starts with a pattern of random dots and gradually changes that pattern into an actual image when it recognises specific aspects of that image.
The visual style of the image is set through the description, varying from realistic to fantastic. In the example below, the images are generated from the description “An astronaut riding a horse”; the first description ends with “as a pencil drawing” and the second one “in photorealistic style.”

DALL-E 2 can also take an original image, make edits and create different versions based on the original, using natural language descriptions. Changes to the original image are applied whilst taking into account shadows and textures of the original image.

DALL-E 2 in turn has sparked a number of AI projects, all building on DALL-E 2’s diffusion process. Tools like Midjourney and Craiyon are based on DALL-E 2 and intend to make image creation using generative AI more accessible to the mainstream public.

Whereas DALL-E 2 charges for the usage of its image models, projects like Stable Diffusion are open source, which means that people can freely use this code and embed into their own applications. The downside of these models being open source is that it invites all kinds of less ethical applications. Take Unstable Diffusion which uses text to generate pornographic images, for example. But one can also imagine how the models will be used for expressions of violence, harassment and hatred. Despite Stable Diffusion having restrictions built in, these can be circumvented when building on the open source code. The main concerns associated with generative AI are thus twofold: (1) loss of artistic control / ownership and (2) inciting hatred, misinformation and violence at scale.
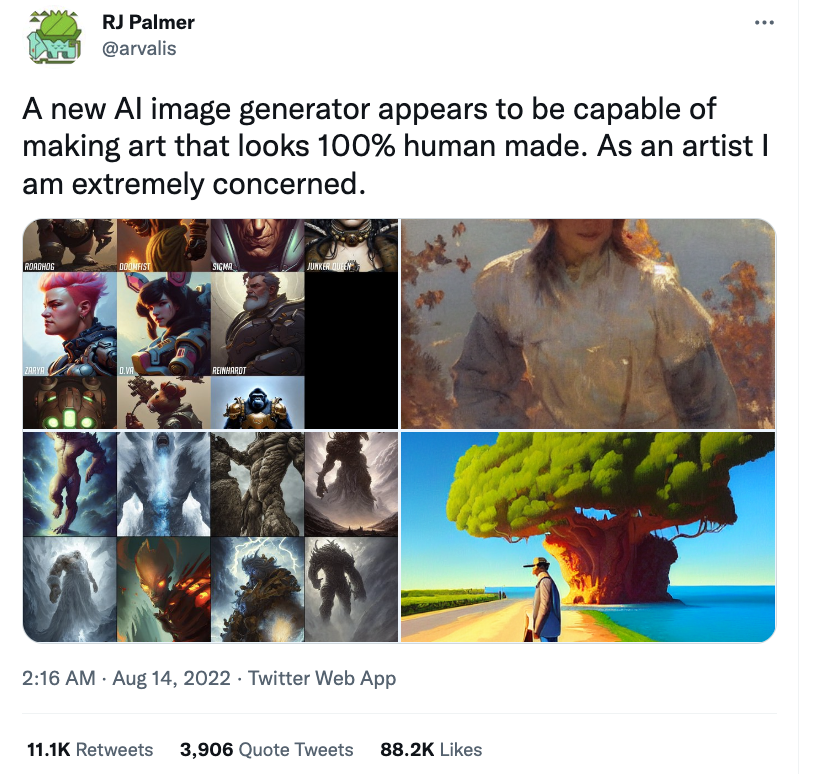
These concerns will no doubt grow stronger as the applications of generative AI grow in popularity and become more production ready. Like the Internet, it’s hard to govern the application of the different AI models, but given the potential impact of ‘image synthesis’ technology I expect closer scrutiny of the underlying AI models and its usage.
The other aspect to consider here is the cultural bias present in most AI models, with some notable and harmful examples coming out of open source AI communities like Huggingface and Stable Diffusion.

The absence of the safeguards to correct cultural biases is one of the reasons why companies like Google haven’t yet released their generative AI models to the wider public. Alex Ratner, CO-Founder and CEO at Snorkel AI, points out that these AI models aren’t yet ready to be put into production by enterprise. For now, labelling the training data is a key factor in generative AI models like DALL-E 2 and Imagen being ready to be deployed to and adapted by enterprise.
Main learning point: The promise of automated image generation using machine learning feels immense and game changing. However, a number of big problems that are inherent to this democratisation of content creation will need to be addressed: built-in safeguards to avoid unethical usage as well as making these AI models adoption ready to adopted by businesses and the larger public.
Related links for further learning:
- https://machinelearningmastery.com/what-are-generative-adversarial-networks-gans/
- https://venturebeat.com/ai/dall-e-2-the-future-of-ai-research-and-openais-business-model/
- https://openai.com/dall-e-2/
- https://arstechnica.com/information-technology/2022/09/with-stable-diffusion-you-may-never-believe-what-you-see-online-again/
- https://venturebeat.com/ai/how-2022-became-the-year-of-generative-ai/
- https://techcrunch.com/2022/10/18/ai-content-platform-jasper-raises-125m-at-a-1-7b-valuation/
- https://arstechnica.com/information-technology/2022/11/openai-debuts-dall-e-api-so-devs-can-integrate-its-ai-artwork-into-their-apps/
- https://ai.googleblog.com/2022/11/infinite-nature-generating-3d.html
- https://bakztfuture.substack.com/p/statement-on-stable-diffusion
- https://techcrunch.com/2022/11/17/meet-unstable-diffusion-the-group-trying-to-monetize-ai-porn-generators/
- https://www.contentgrip.com/copysmith-ai-copywriter-funding/
- https://imagen.research.google/
- https://replicate.com/stability-ai/stable-diffusion/examples
- https://www.howtogeek.com/823337/how-to-create-synthetic-ai-art-with-midjourney/
- https://rossdawson.com/futurist/implications-of-ai/future-of-ai-image-synthesis/
- https://bdtechtalks.com/2022/10/17/dalle-2-microsoft-azure/
- https://www.sequoiacap.com/article/generative-ai-a-creative-new-world/
- https://greylock.com/greymatter/jumpstarting-data-centric-ai/

14 responses to “What does generative AI have in store for us?”
[…] a a new machine learning model by OpenAI that can create images from a scene written in words. In my blog post, I explained how DALL-E 2 introduces a form of generative AI, enabling users to create images from […]
[…] history and human activity. One can look at any technology, whether it’s the mobile phone or generative AI and see how Kranzberg’s Six Laws […]
[…] such as “a calming violin melody backed by a distorted guitar riff.” Through a generative adversarial network MusicLM generates sound snippets based on text […]
[…] avatars generated of some female Lensa users, which Lensa has been trying to address through its generative AI, updates to its privacy policy and risk warnings like the one above. I then need to select my […]
[…] summary of Duolingo Max before using it – Duolingo using generative AI to help its users learn new […]
[…] been nearly a year since I first wrote about generative AI and it seems like not a day goes by where there isn’t a launch of a generative AI […]
[…] been nearly a year since I first wrote about generative AI and it seems like not a day goes by where there isn’t a launch of a generative AI application. […]
[…] talk a lot about the new innovations enabled through generative AI, but we haven’t talked as much about how we expect users to interact with AI applications. […]
[…] types of motion, and accurate details of the subject and background. Similar to Google Gemini and DALL-E, you give Sora a text prompt and it will generate a video for you. OpenAI claims that the model […]
[…] for decades, but the main shift that we’re in the midst of is a shift from retrieval to generative […]
[…] years, however the principle shift that we’re within the midst of is a shift from retrieval to generative […]
[…] many years, however the primary shift that we’re within the midst of is a shift from retrieval to generative […]
[…] My summary of Websim before using it – I believe that Websim helps create a website in no time, using generative AI. […]
[…] consistent output quality – For instance, GANs might produce visually striking images marred by imperfections. Language models can generate text […]