When I first heard the term “inference computing”, I wasn’t entirely sure what it meant. So I looked into it, and the concept turned out to be surprisingly relevant to the way I work with AI tools every day.
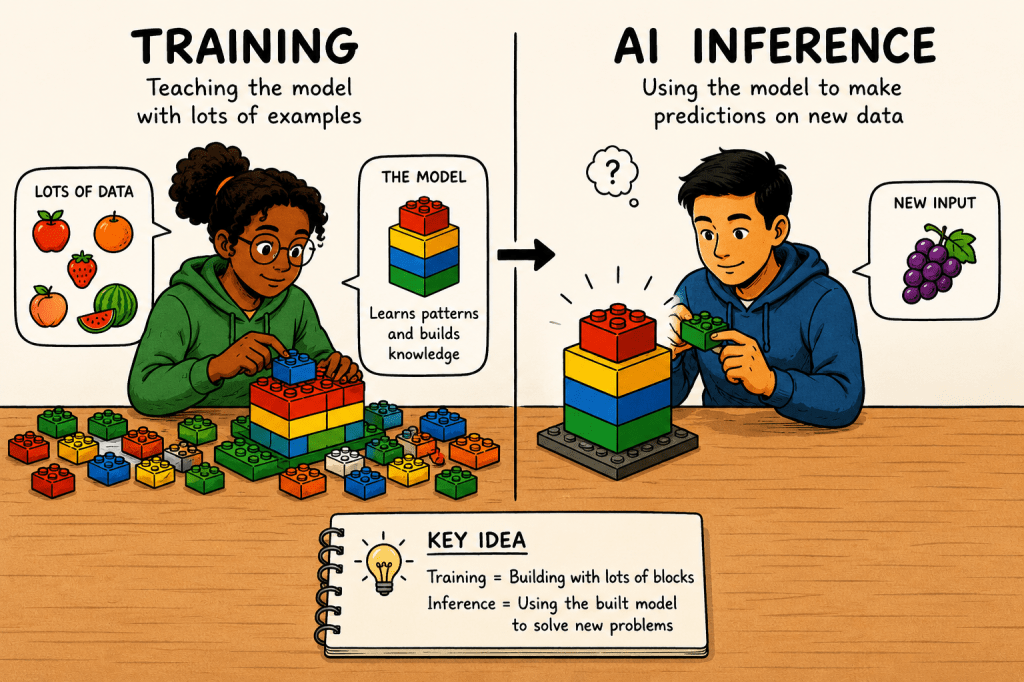
In simple terms, AI inference is what happens when an AI model that has been trained on large datasets starts applying that learning to new, real-world data it has never seen before. Training is the phase where the AI learns patterns from curated data. Inference is what comes after: the model using those patterns to reason, predict, and generate responses on the fly. Think of it like the difference between studying for an exam and actually sitting the exam. Training is the studying; inference is the moment of application.
Understanding inference matters for product managers because it directly shapes what AI tools can and cannot do, and why. Whether you are using Claude Code, Cursor, Cowork, or OpenClaw, you are interacting with inference in action every time you prompt an AI.
What AI inference is good at
AI models infer patterns from enormous amounts of data, which makes them strong at tasks where those patterns are well established. In the context of coding agents like Claude Code and Cursor, that translates to spotting patterns and anomalies, such as flagging unusual logic in code or identifying security vulnerabilities.
Applying widely used conventions around security, performance, and API integration. And generating UI layouts or basic UX structures from rough prompts, because these follow common, learnable patterns.
Where inference has clear limits
Inference is only as good as the patterns the model has seen. Where your context is unique, the model has less to draw on. That shows up in a few specific ways. Domain-specific business logic is a good example. If your product has rules or workflows that are particular to your organisation, the AI has no prior exposure to them.
Similarly, design implementation that follows your specific brand guidelines or design system will not emerge naturally from inference alone. And nuanced user flow requirements, especially those tied to specific business rules, often need to be spelled out explicitly rather than inferred.
This is something I am actively learning to navigate: how much context to give Claude Code and Cursor upfront, so that the AI can handle the common patterns whilst I fill in the domain-specific gaps it cannot reasonably infer.
Cloud vs local inference: a trade-off worth understanding
One dimension of inference that I believe is becoming increasingly relevant for PMs is where inference actually happens: in the cloud or on your own device.
Cloud inference means your prompt is sent to a remote server, processed by an LLM, and the response is returned to you. This is how most AI tools work today, including Claude, Gemini and ChatGPT. The advantages are significant: you get access to the most capable models, with no hardware requirements on your end. The trade-offs are latency (you are dependent on a network round trip), cost (cloud API calls add up at scale), and data privacy (your inputs leave your device).
Local inference runs the model directly on your own machine. Tools like OpenClaw and Claude Cowork support local models alongside cloud ones, which means your data stays on your device and there is no network dependency. The trade-off is that locally run models are generally smaller and less capable than their cloud equivalents, and you need reasonable hardware to run them. There is also a practical constraint that catches people out: local inference only runs while your machine is on. If you close your laptop, any background tasks stop with it. Hence why people hook up their machine up to a Mac Mini or set up a Virtual Private Server – Hostinger or Hetzner to be able to run certain tasks continuously.
For PMs working in enterprise environments, there is a third option worth knowing about: mirrored inference. This is an approach where you work on local files, but those files are automatically synced and shared with colleagues, with shared values, principles and an index kept in a file like CLAUDE.md. It is a way of getting the speed and data control of local inference whilst keeping enough shared context for team collaboration. Think of it as a middle ground: local execution, but with the connective tissue that facilitates collaboration.
For PMs thinking about AI product decisions, this trade-off comes up more than you might expect. A customer-facing AI feature that handles sensitive data may point strongly towards local inference. A developer tool where raw capability matters most probably favours the cloud. And a team-based knowledge workflow, where people need both privacy and collaboration, may point towards a mirrored approach.
Ultimately, three factors determine the quality of any inference experience: speed and latency, cost, and output accuracy. Getting the balance right between those three depends heavily on your use case, your users, and where inference is running.
Main learning point: AI inference is the moment an AI model applies what it has learned to new, real-world situations, and understanding it helps PMs make better decisions about which tasks to delegate to AI and which ones need more explicit human input. The emerging choice between cloud and local inference adds another dimension to this, with real implications for product cost, privacy, and capability.
Related links for further learning:
