My summary of Eventual before using it — Eventual is a multimodal data processing platform designed to power AI-based products and features.
How does Eventual explain itself in the first minute? “Revolutionising the way you work with data” is the main strapline on Eventual’s website, and the short explainer video wastes no time making the case. It introduces Daft — a single API pipeline framework that turns raw multimodal data from images, video, audio, and text into vectors, labels, and structured outputs.
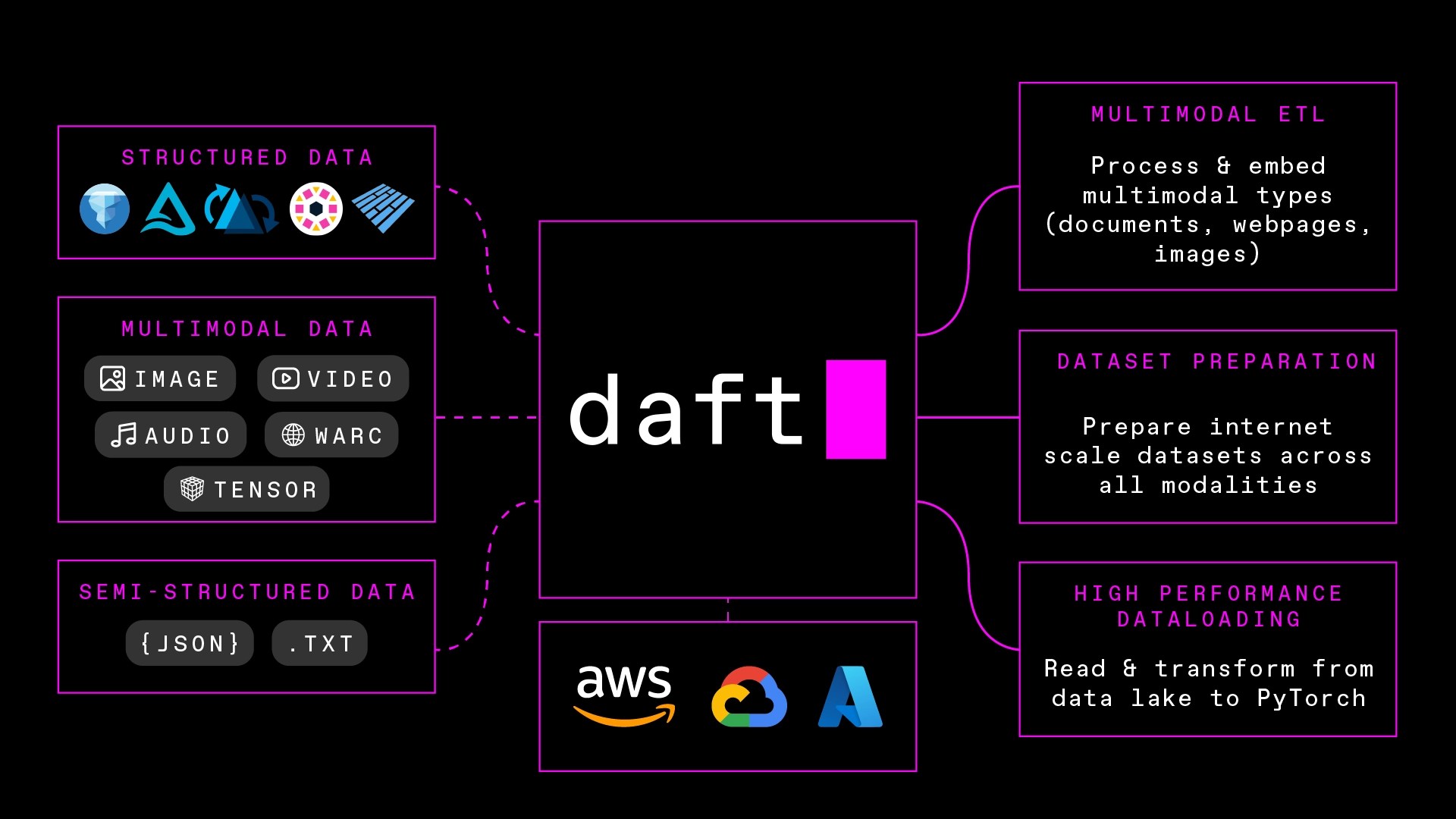
How does Eventual / Daft work? The Daft framework combines four core capabilities into one pipeline:
- Data ingestion — The process of importing raw data from various sources (databases, APIs, files) into a system where it can be processed. Think of it as the “front door” through which all your data enters the pipeline.
- Data chunking — Because AI models can only process a limited amount of text at once, chunking breaks large documents into smaller, manageable pieces. The trick is chunking smartly — too small and you lose context, too large and you overwhelm the model.
- AI embeddings — Embeddings are numerical representations of text, images, or audio that capture semantic meaning. An embedding model converts data into a vector — essentially a long list of numbers, each dimension capturing some aspect of meaning — which is what allows AI to search and retrieve information based on meaning rather than keyword matching.
- Multimodal transforms — The processing steps that convert different content types — text, images, audio, video — into a common format an AI model can work with. This is what allows Eventual to handle a PDF, a diagram, and a voice note within the same knowledge base.

Daft enables companies and developers to work with diverse data formats within a unified framework. The key difference from traditional DataFrame systems like Pandas is that Daft is designed specifically to handle unstructured data — images, audio, embeddings — natively, rather than relying on external libraries.
One distinction I found particularly interesting is between lazy and eager execution. Traditional systems like Pandas execute commands immediately (eager). Daft applies lazy execution instead, deferring computation until a result is actually needed. This means it can optimise the full transformation pipeline upfront, avoiding unnecessary calculations and reducing memory usage — a meaningful advantage when working at scale.
Scalability is another differentiator. Where traditional systems are typically constrained by a single machine’s RAM, Daft is built to scale from local to cloud environments from the outset.
| Feature | Eventual DataFrames (e.g., Daft) | Traditional DataFrames (e.g., Pandas) |
|---|---|---|
| Primary Focus | Large-scale AI, ML, & Multimodal data | In-memory, interactive data analysis |
| Evaluation | Lazy (computes only on action) | Eager (computes immediately) |
| Architecture | Python-native + Rust (distributed) | Python + C (single-node) |
| Data Scope | Larger-than-memory / Distributed | Fits in local RAM |
| Multimodal Support | Native (images, audio, embeddings) | Limited (usually requires external libraries) |
| API | SQL-like, DataFrame API | Wide range of manipulation tools |
Eventual operates in a crowded space, with well-established competitors including Databricks and Pinecone. Its native multimodal support and ability to handle unstructured data at scale are the clearest differentiators — particularly relevant for teams building large-scale AI applications with diverse data inputs.
Main learning point: Eventual’s Daft framework tackles one of the probably less glamorous but genuinely hard problems in AI product development: getting diverse, messy, real-world data into a shape that AI models can actually use. For teams building on top of AI, the ability to handle text, images, audio, and video within a single pipeline — without stitching together multiple tools — is a meaningful step forward.
Related links for further learning:
